Instala tu asistente local de IA¶
Si deseas instalar tu propio asistente de inteligencia artificial en tu equipo, de forma gratuita, sin crear cuentas, exponer tus datos y todo bajo tu control, esto es posible gracias a Ollama. Disponible en Windows, Linux y Mac. Te explico cómo disponer de los asistentes de Qwen, Llama y Deepseek.
Requisitos de hardware para tu asistente de inteligencia artificial¶
Lo primero que debemos tener en cuenta es que Ollama no posee requerimientos de hardware específicos, y estos dependen de los modelos de lenguaje (o inteligencia artificial) que vayas a usar. Lo más importante para saber estos requerimientos, es el número de parámetros del modelo, que típicamente verás las menciones de billones o trillones de parámetros (en el contexto del sistema internacional, sería miles de millones y billones, recuerda que en inglés no existe “miles de millones”). Los grandes modelos de lenguaje (LLM) disponibles en los servicios comerciales disponen de “trillones” de parámetros y requieren de servidores no solo con una gran potencia de CPU, sino también de GPU. Si el modelo es de “billones” de parámetros es posible considerar usar equipos locales (nuestros computadores), pero si están cerca de los 100 “billones” de parámetros vas a necesitar equipos de última generación con RAM superior a 64 GB y varias tarjetas gráficas RTX. Entre los 4 “billones” y 20 “billones” de parámetros puedes considerar su uso en equipos gamer, desde una sola tarjeta gráfica RTX (serie 2000 en adelante) y 16 GB de RAM, cómo es mi caso (pero más de 10 “billones” de parámetros se ejecutan de manera forzada e incluso genera el cierre de aplicaciones abiertas). Si tu equipo no posee GPU, pero tienes al menos 16 GB de RAM, podrías usar con cierta fluidez los modelos de menos de 4 “billones” de parámetros. En la medida que reduce el número de parámetros se requiere menor recurso de hardware, pero también son modelos de menor precisión.
Atención
Con la salida de deepseek-r1 se ha mencionado mucho sobre lo económico que es y la facilidad de ejecución en local, sin embargo esto es importante respecto al entrenamiento del modelo, y no respecto a la consulta del modelo. Los modelos livianos de deepseek-r1 son modelos destilados de Qwen y Llama, por lo cuál, si te funciona Deepseek, te funcionan los originales y en mi opinión, son mejores.
Instalación de Ollama¶
Para instalar Ollama, si usas Mac o Windows, puedes usar los instaladores descargables disponibles en su sitio web, pero, si usas Linux, puedes ejecutar en tu consola directamente:
curl -fsSL https://ollama.com/install.sh | sh
Esto tomará unos minutos, y detectará la configuración adecuada para el uso de tarjeta gráfica si poseemos una.
Al terminar, tendremos el gestor de modelos de lenguaje listo para instalar y ejecutar nuestro primer modelo.
Instala un modelo de lenguaje con Ollama¶
¿Pero cuáles modelos de lenguaje podemos instalar? Tenemos a nuestra disposición los modelos publicados en la web oficial de Ollama en la sección de búsqueda de modelos. Las grandes familias que podemos identificar son:
Qwen: Familia de modelos producidos por Alibaba (China). Destaco las capacidades de la serie 2.5, general y de código.
Mistral: Familia de modelos producidos por Mistral AI, muy cercanos a la comunidad académica, con una fuerte apuesta desde el inicio en el open source. Destaco el modelo especializado en matemáticas.
Phi: Familia de modelos producidos por Microsoft. La apuesta interesante de Microsoft con modelos “livianos” con capacidades máximas.
Llama: Familia de modelos producidos por Meta (Facebook). Se destaca el camino con la serie 3.2 para modelos livianos y su asistente de código “Codellama”.
Deepseek: Familia de modelos producidos por Deepseek, empresa bajo la cobertura de High-Flyer (China). Debo decir que no tengo una buena experiencia con deepseek, confunde el lenguaje, toma caminos complicados a problemas simples, es menos preciso. Pero me parece interesante su comportamiento por defecto de mostrar el “razonamiento” previo a la respuesta final, y que ante instrucciones muy claras puede ser guiado fácilmente.
Para instalar y ejecutar un modelo de lenguaje, procedemos con la opción run de ollama, indicando el nombre del modelo y el número de parámetros separado por :, y si no se indica el número de parámetros tomará la versión por defecto. Ejemplo, si queremos instalar Qwen2.5 de 7 “billones” de parámetros, será:
ollama run qwen2.5:7b
Esta instrucción la veremos en la página de modelos cuando seleccionamos del listado el número de parámetros del modelo, hacia la derecha.
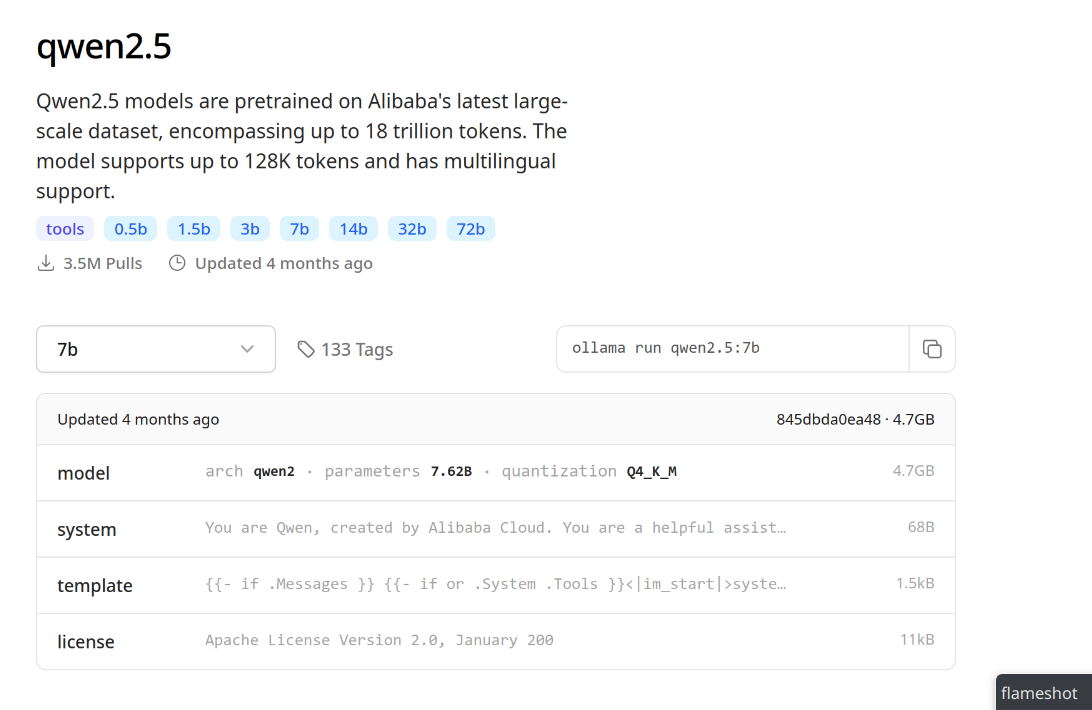
Información del modelo Qwen2.5 en la web de Ollama.¶
Otros ejemplos pueden ser:
ollama run llama3.2:3b
ollama run phi3.5
ollama run deepseek-r1:7b
Consulta tu asistente de inteligencia artificial¶
Una vez instalado, nos habilita la consola para el ingreso de consultas. Pero si queremos volver, basta con ejecutar nuevamente con la opción de run. Ejemplo:
ollama run qwen2.5:7b
Escribimos nuestra consulta y presionamos Enter ↵.
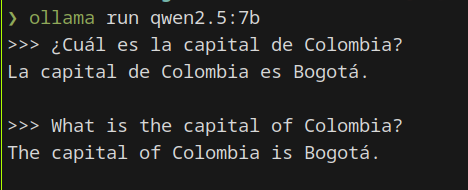
Consulta con el modelo de lenguaje Qwen2.5 en español y en inglés.¶
Si deseas salir de cualquier asistente con Ollama, debes digitar /bye y Enter ↵.
Otras opciones útiles de Ollama¶
Si deseas listar los modelos instalados, puedes ejecutar ollama list, y para borrar un modelo que ya no necesitas (y liberar espacio de disco), puedes usar ollama rm seguido del nombre del modelo tal cómo es listado con ollama list. Ejemplo, ollama rm deepseek-r1:14b.
Interfaz web tipo ChatGPT¶
La terminal no es algo amigable con todos los usuarios, así que puedes instalar Open WebUI y disponer de una interfaz similar a ChatGPT que te permite organizar conversaciones, agregar colecciones de archivos de conocimiento que sean usados para analizar o responder preguntas sobre estos, y que te permita seleccionar el modelo que deseas usar para una conversación específica. También ofrece una opción de pruebas que te permite evaluar los distintos modelos que tienes instalados.
Si dispones de uv instalado, puedes instalarlo de la siguiente forma:
uv tool install --python 3.11 open-webui
Y después de esto ejecutar el servidor local con open-webui serve. Usa la URL indicada al ejecutar para pegar en la barra de dirección del navegador (por defecto es http://0.0.0.0:8080).
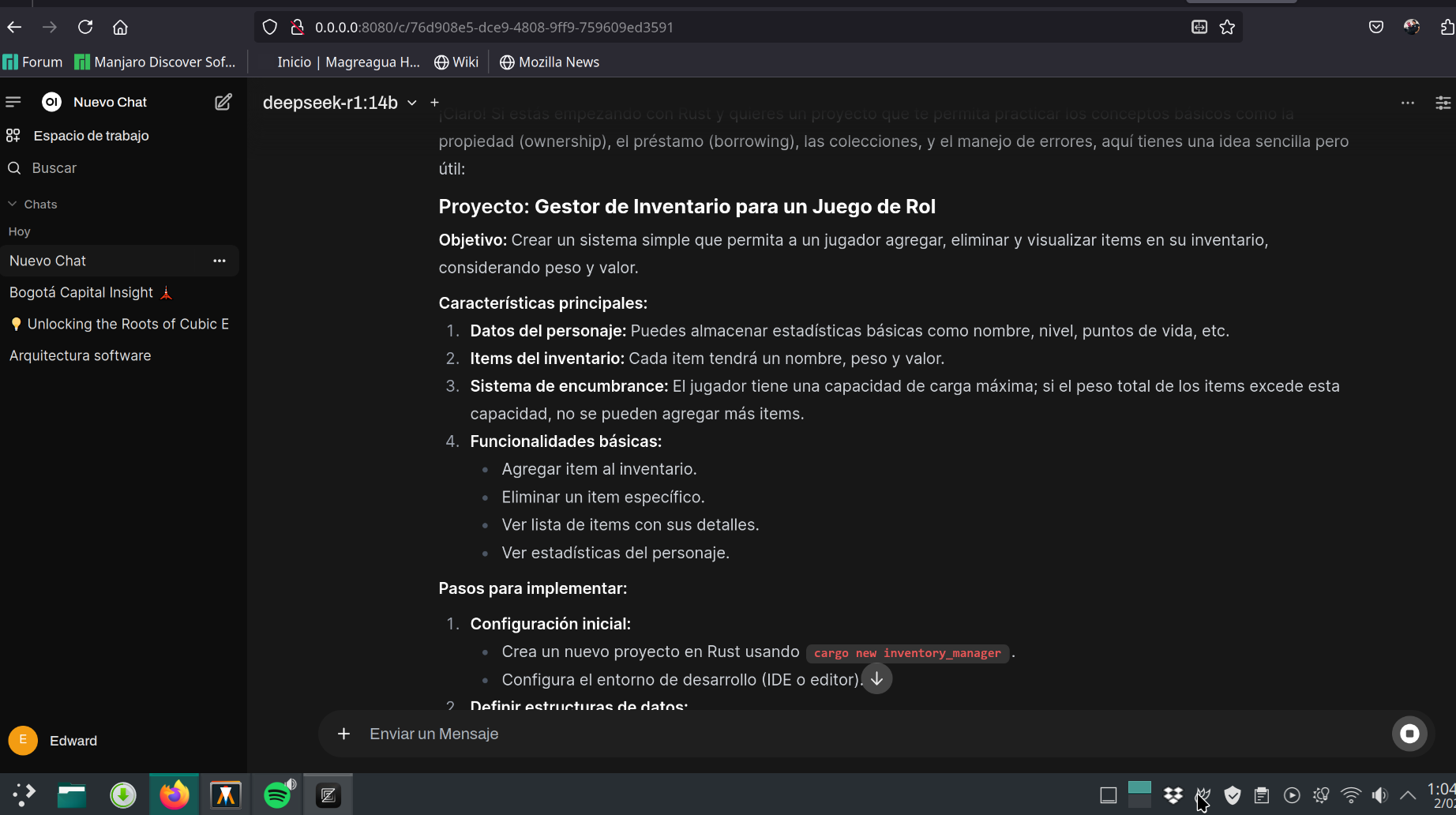
Vista previa de Open Web UI en la organización de conversaciones con modelos de lenguaje.¶